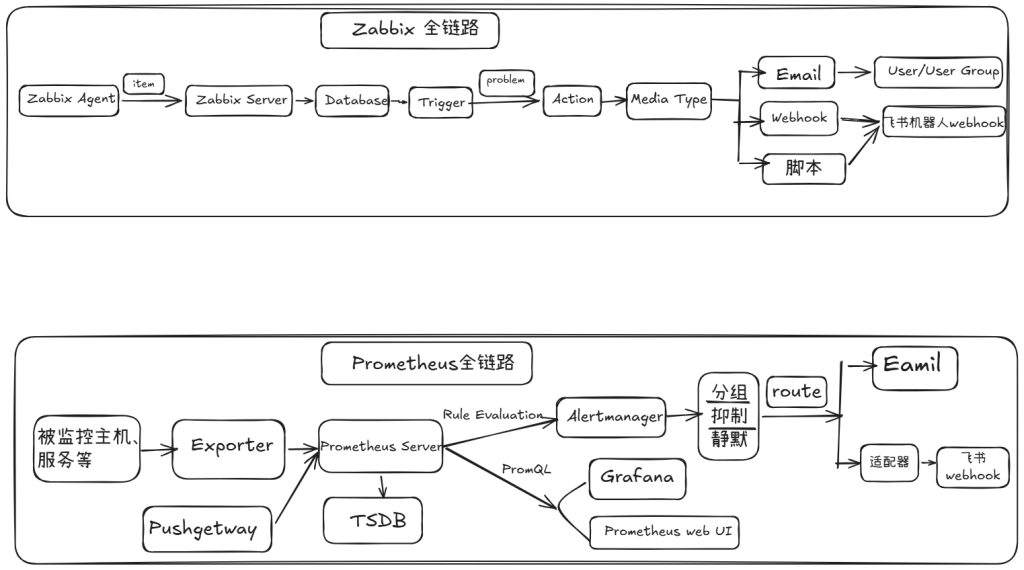
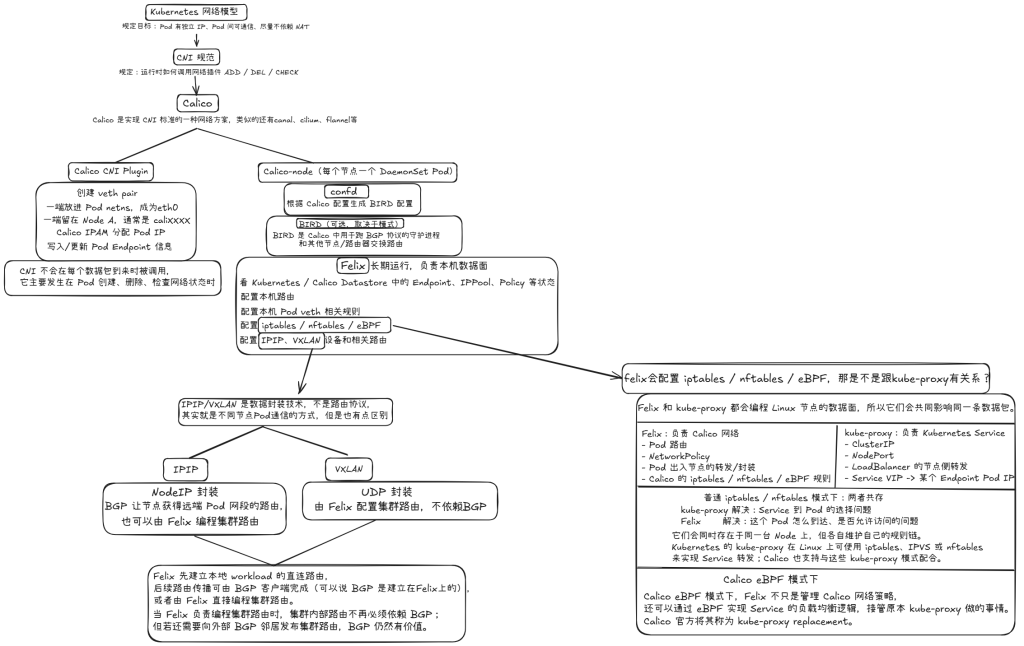
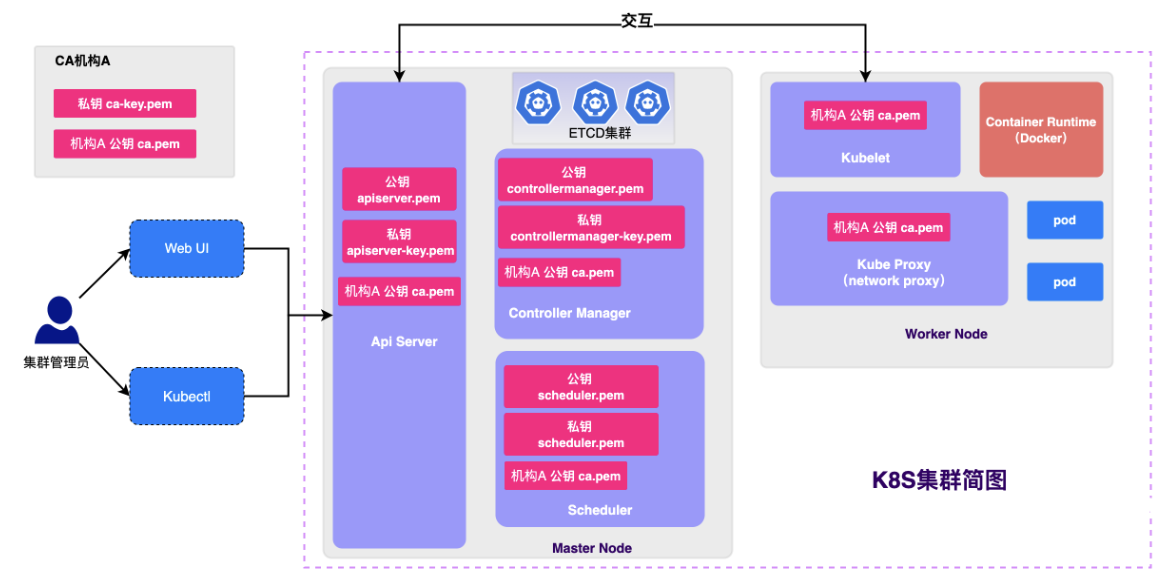
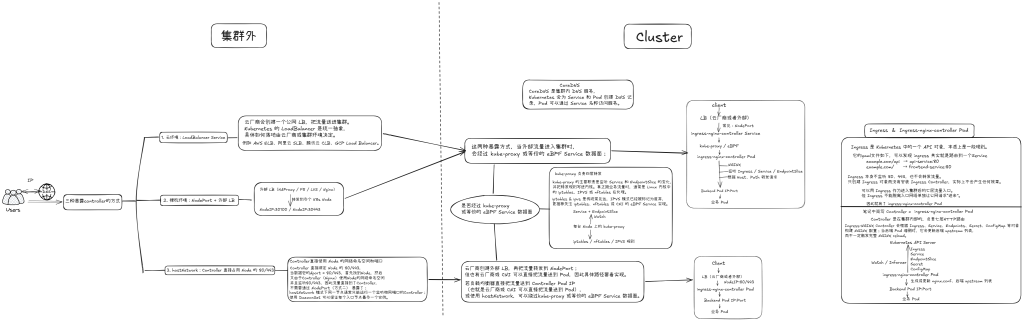
前言
最近发现这全局的一个思维很重要,不是对每个知识点都学得非常非常好,重要的是学了这个知识点有什么用,在整个知识体系中扮演什么角色。
因此我开始不断去学习云计算、SRE、互联网架构,这些东西之间到底有什么联系,学习它们需要什么技术栈,如何将整个知识体系搭建起来,知道我学的每一个技术是干啥用的……
这次我将我最近学习的所有东西全都串起来,从互联网架构开始、如何不断演进、最后到为什么要上云、最后SRE 需要干些什么
互联网架构
本质
让大量用户稳定、快速、安全地访问服务,并让系统在流量变大、数据变多、机器故障、业务复杂时仍然能扛住。
这其实和我们SRE的目标很像了,SRE 就是SRE就是用软件工程能力解决运维问题,让系统既可靠,又能快速迭代
演进
单机
比如我买了一个服务器,然后基于 LAMP/LNMP架构 做了一个网站,这个其实就是单机架构。但是刚开始访问量很少,但是业务实在过于优秀,用户访问量多了,一个单机扛不住了,应用和数据库经常抢资源,这个时候怎么办?
那就是加机器,我们把数据库和应用拆分开,应用服务器处理请求和业务逻辑,数据库服务器存储数据和做一些IO操作(简单来说就是数据传输),这个时候两者各司其职,互不干扰,可用性也提升了
集群与负载均衡
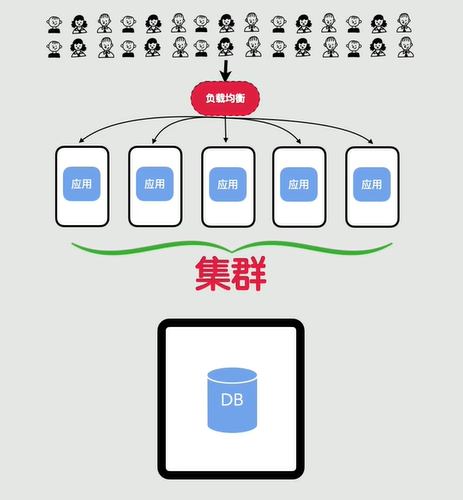
好景不长啊,用户访问量越来越多,一台单机服务器完全处理不过来了,就算所有配置都拉到满也不行了,数据库也扛不住大量查询,这个就叫做高并发,怎么办呢?
那就继续加机器,比如原来我一台应用服务器最多处理100个请求,现在有1000个请求打过来,我就再加9台机器,部署一摸一样的代码和环境,这个就叫做集群了
光加机器也不行,还有一个问题就是我们怎么控制流量分配到每台服务器呢?
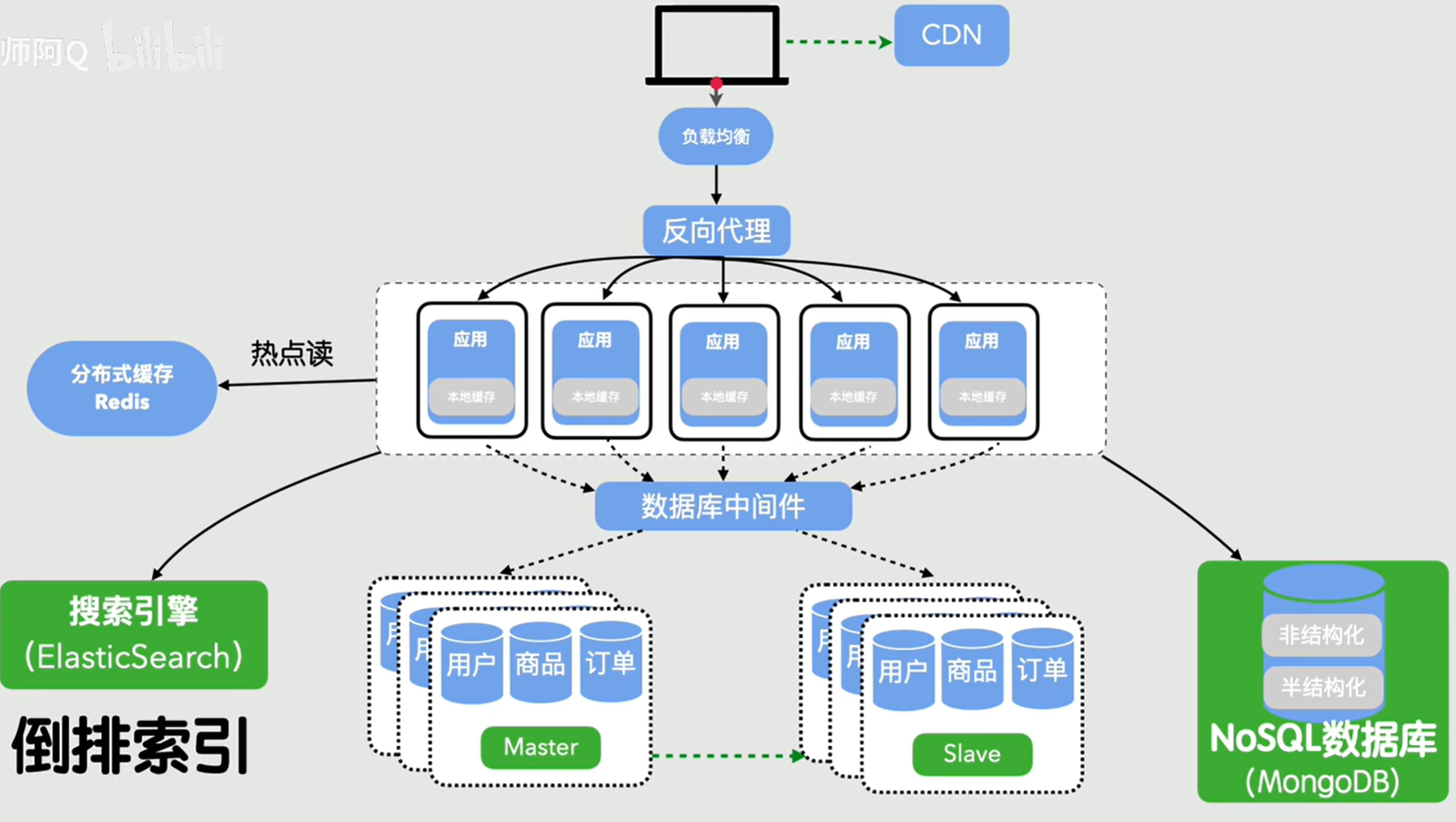
这个时候我们来做一个中间层,就是它能将请求均匀的分配到每台应用服务器,这个就叫做负载均衡。这个其实也是一台服务器,我们叫它反向代理,客户端的请求先到达反向代理,反向代理根据配置中的调度算法,将流量分发给后端服务器
如果流量越来越大,我们就继续加机器,这其实叫做水平扩展,不够就加
如果集群中的一台服务器挂了,它自动就屏蔽流量,其他机器顶上去,保证系统不会崩,这个就叫做高可用
多级缓存
上面说完,我们的应用服务器抗住了,数据库呢,大量请求打过来,数据库崩了的话是最严重的,影响整个业务
我们先说应用查询数据库的原理:
- 应用把查询请求发给数据库
- 数据库就会去内存缓存区找数据,找到了直接返回,没找的话就去磁盘框框一顿查
- 找出来发到内存缓冲区,最后返回给应用
我们都知道,读缓存比读磁盘快几千几万倍,那可不可以直接从磁盘的内存缓冲区读呢?不可以的,因为实在是太小了,那怎么办?
我们不妨将这个内存缓冲区单独拿出来,然后放大,经常访问的热数据都放到这个里面,这样就极大提高了查询效率,这个时候,它不在叫内存缓冲区,而是叫做缓存,缓存是什么快什么常用就存什么数据,不只是数据库里的东西
这里缓存有三种:
- 浏览器缓存(L1 客户端缓存)
- 应用服务器本地缓存(L2 进程内缓存)
- 分布式缓存 Reids(L3 集中式缓存)
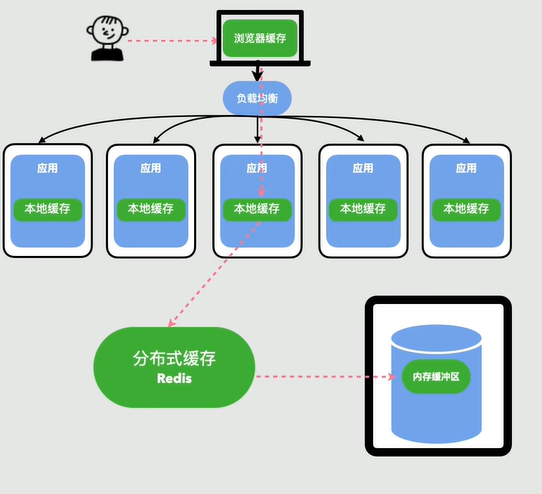
用户每次请求先去浏览器缓存找,没有就去本地缓存找,再没有就去分布式缓存找,在没有的话就去数据库了。
其实绝大多数请求都到不了数据库,一般在缓存就能找到并直接返回,因此数据库压力很小,就算数据库真的挂了,缓存也能撑一会,可用性大大提升
但是缓存其实也有一些经典问题:缓存雪崩、缓存击穿、缓存穿透等,这个自己可以自行补充学习,这里不过多介绍了
数据库
上面说完缓存解决了热点读,减少了数据库压力,提高了查询效率,那如果一些非热点读和写操作请求还是到了数据库
数据库有个特点,那就是写比读慢得多,写会有锁,并发一高,就需要排队,严重导致雪崩
这个时候我们可以做读写分离操作,主库负责写操作,从库负责读操作,然后通过主从复制保持主从数据一致性,解决了读写相互阻塞的问题。而且如果主库挂了,还可以故障转移,可用性也提升了
随着时间越来越久,数据库的数据量越来越大,单库单表可能扛不住,这个时候我们可以将数据库拆分,这个叫做拆库拆表,比如按业务拆分,什么用户库,商品库、订单库等,这些都不干扰,这个叫做垂直分库。一张大表拆成多张小表,分散数据库压力,这个叫做水平分表。
这里数据库从单点变成分布式,存储和并发能力可以无限扩展了
传统数据库遇到模糊查询、全文搜索多维统计有点力不从心了,比如电商搜商品、新闻热搜用like慢到死了,如何解决?
利用倒排索引让搜索秒级响应,这个叫做搜索引擎(ES),还有专门存非结构化、半结构化数据,而且支持高并发易扩展,这个叫做Nosql 数据库。这时系统终于从只能简单增删改查变成支持复杂检索与分析了
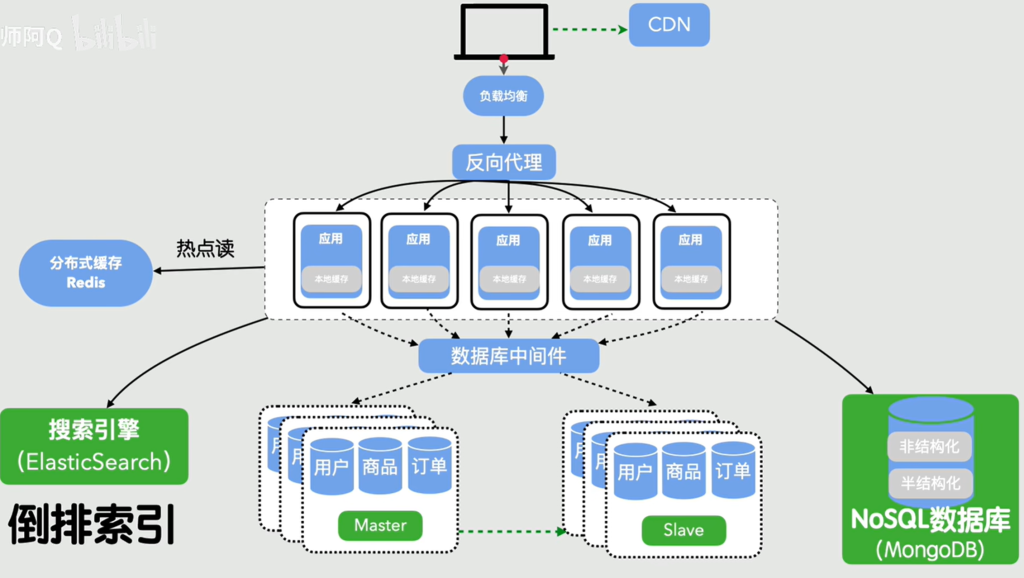
CDN
后面网站访问的客户来自全国各地,你的网站服务器在湖北(源站),但是有新疆的用户想要访问你的网站,但是太远了,直接访问的话是非常慢的。这个时候我们就可以将我们的网站的静态资源提前放到全国各地的节点,用户访问我的网站的时候,请求就不需要来湖北了,直接在离新疆那个用户最近的节点返回对应内容,这个就是CDN。就好比快递,我们拿快递不需要去生产地拿,而是直接在楼下快递站拿。
分布式架构
上面说完数据库层,随着流量愈来愈大,应用层也出现新问题了。
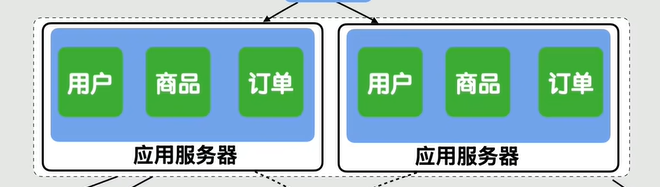
比如我的网站现在成为了一个集用户、商品、订单于一体的大平台,但是现在我只有两台应用主机的集群,现在所有功能代码全都在一个应用里,这个就是常说的巨石应用。这时,如果改一行用户相关的代码,就需要全量发布整个应用;多个开发同时修改代码,天天对冲;想要给商品服务或者订单服务加加机器抗流量,整个应用就需要一起扩容,资源大大浪费。怎么办呢?
还是拆,按照业务边界将这个整个应用一刀一刀切开,用户相关的做成独立的用户系统、商品、订单也都独立做成一个系统,每个系统单独部署、单独发布、单独扩容,互不影响,这个叫做分布式架构(将整个业务拆分成多个子业务)
分开之后,这些系统之间如何调用,如何通信呢?RPC远程调用来了,它让跨机器的系统调用像调用本地代码一样。但是服务愈来愈多,愈来愈复杂,如何快速找到目标服务并调用它呢?这时就需要一个总管,叫做服务注册和发现中心
还有一个问题,那就是这些服务之间相互调用、相互等待,如果一个服务卡住了,整个链路全都跟着堵死了,这个就是雪崩,如何解决?
消息队列 MQ
怎么才能让服务之间不相互等待呢?这时就需要MQ消息队列了,服务想要去调用另一个服务,直接把调用的消息丢到消息队列中,不需要等待,另一个服务自己去MQ里面取就可以了,这就实现了解耦(不同服务之间互不影响),就算一个服务挂掉了,消息也不会丢掉,直到恢复再去处理,还有就是当流量突增,还能将消息存起来,按照能力慢慢消费,这个就叫做削峰填谷
微服务架构
上面说完分布式架构,我们按照业务边界拆成很多子业务,但是拆的还是不够细,我们还可以拆。比如说,用户里面还有登录、注册、会员、地址等信息,不同的团队设计的想法可能不相同,还有想给会员服务加机器,那就需要整个用户服务加机器,也是浪费资源。那继续拆,每个服务都做成单独的服务,这样就可以独立开发、独立发布、独立扩容、互不干扰,这套架构就叫做微服务架构。这样一来,我想给哪个微服务加机器就加,不用整个服务都加,这样就可以减少资源浪费,还有就是就算一个微服务挂掉了,也不会拖垮整个网站,还有开发效率极大提高。
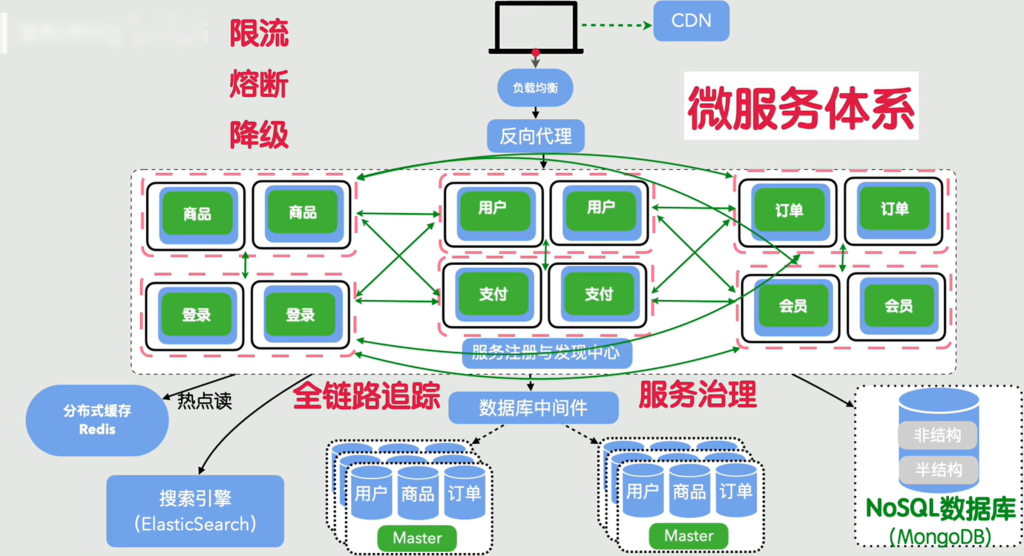
微服务体系
说完微服务架构,可以发现整个架构越来越复杂,服务越来越多,调用关系像蜘蛛网,出了问题找不到在哪,因此我们可以加上链路追踪
流量太大呢?加上限流、熔断、降级,自动保护系统
服务太多不好管,加服务治理、统一监控、日志、告警系统
上面东西全都加起来,我们的系统就变成了大厂标准的微服务体系,抗住千万级亿级流量都不在话下
云原生架构
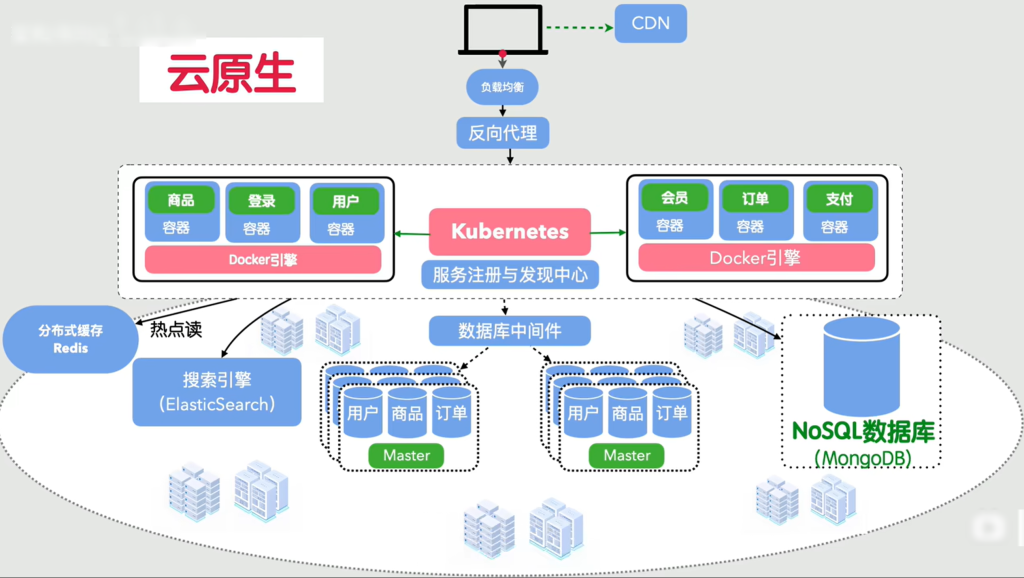
这时的传统运维都要哭了,服务这么多,这么复杂,从原来的几个应用变成几百个微服务,每个服务上线都要配环境、装依赖、调参数,稍微错就gg,本地能跑,换地方就跑不了。大促前需要紧急扩容几百台机器,一台台配环境完全赶不上,直接gg,就算赶上了,结束后缩容一台台清理也很麻烦,效率极低,怎么办呢?
把服务和它需要的运行环境一起打包成一个密封盒子放到哪台服务器都能直接跑,这个密封盒子就是Docker 容器,不用再配环境把每个微服务的代码依赖配置环境全部打包成一个镜像,一次打包到处运行,解决了环境不一致的世纪难题
这样几百个容器谁来管理呢?我们的Kubernetes,k8s 来了,流量高就自动加容器,流量低就自动缩容器,容器挂了自动重启,啥都不用管了
但是我们还时需要购买服务器来预防大促,但是过了大促,一堆机器还是闲置,浪费钱
如何解决?我们将这一整个系统搬到云平台上,就解决了
云平台就像是一个无限大的资源池,服务器、CPU、内存…….想要多少就要多少,按需购买,用完再释放。这样一来底层的什么机房、服务器啥的都不要管了
这时整个互联网架构进入了新时代——云原生架构
从最开始一台小服务器,到如今弹性、自动化、高可用、能无限扩展的现代化架构,不管业务怎么涨流量都能稳稳抗住
云计算
云计算就是把计算、存储、网络、安全、中间件、数据库等 IT 能力,做成可按需申请、弹性扩缩、按量计费的资源池
上面就可以看到云原生就是让应用程序充分利用云计算的弹性、可扩展性和高灵活性的一套架构
为什么要上云?上面就说的很清楚了,解决了”贵、闲、烦”
云计算的五大特性、三大服务模式(IaaS、PaaS、SaaS)、云计算部署模式(公有云、私有云、社区云、混合云)……可以自己去了解,这里不过多介绍了
SRE
SRE就是用软件工程能力解决运维问题,让系统既可靠,又能快速迭代。看你能不能站在业务稳定性的角度,把 Linux、网络、数据库、容器、K8s、监控、发布、故障处理、自动化全部串起来,形成一套能长期保障系统稳定的工程体系
Sre核心职责、目标、具备的能力、特质也不过多介绍了
建议读一下《Google:Sre运维解密》
总结
这里介绍了主要互联网架构的一个演进、其次简单介绍了一下云计算和Sre,具体可以自己去了解。我觉得认识整个互联网架构是及其重要的,学习它的演进,中间的很多改进都是需要学习的,包括最后的云原生,与我的学习方向是匹配的,所以我认为是极其重要的,帮助我日后的学习