前言
如今AI盛行的时代,大家日常生活学习肯定都会使用大模型LLM(理解并生成自然语言)来解决我们的一些问题,比如说ChatGPT,Gemini……那么这背后有哪些神秘的东西呢?今天我就来简单介绍一下RAG(Retrieval-Augmented Generation)——检索增强生成技术吧。
一、为什么要有RAG?
先讲一下LLM的基本原理吧。
首先就是LLM通过预训练,学习网上各种各样的的知识(公开的,全网可查的),然后这些文本转为Token,再Embeddding为向量存储到向量数据库中,最后通过相似度计算,预测下一个Token,最后生成。
这其中Token,Embedding(向量化)是什么?我就不再赘述…….
这其中有什么缺点呢?
如果涉及到一些实时性,一些私有的数据时,LLM很可能就会因为向量匹配相似度不够,在预测时胡说八道,也就是常说的“幻觉”
因此就需要有RAG这个技术了,就是给原本的LLM外挂一个知识库,然后在这个知识库里完成RAG。接下来,我将RAG分解为三个部分,R(Retrieval-检索)、A(Augmented-增强)、G(Generation-生成)。
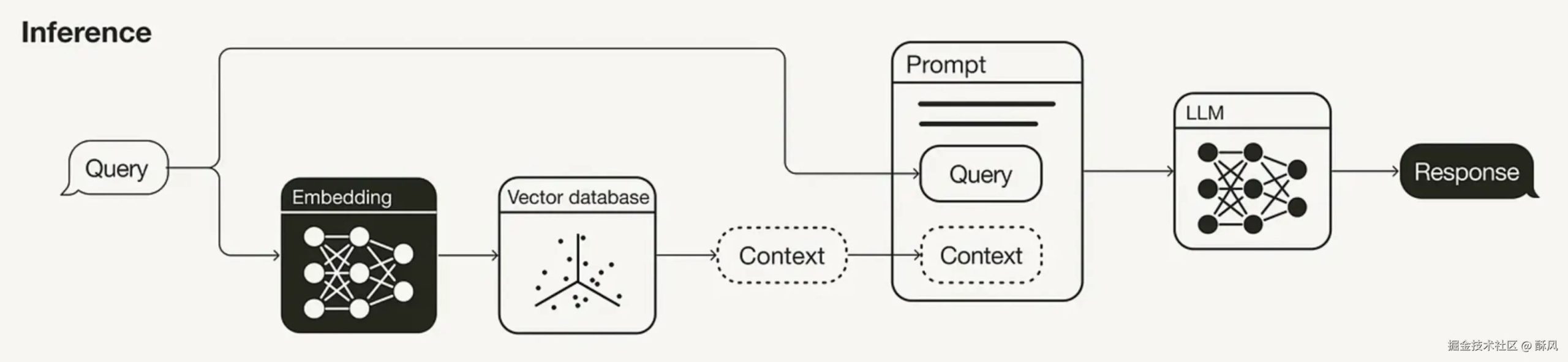
二、RAG – R (Retrieval-检索)
首先对用户的问题进行Embedding,在进行了向量化之后,就可以开始在向量数据库中检索了,检索和用户的问题相似语义的向量。
其实就是一个相似度匹配的问题。
和普通数据库基于关键字的检索不同,向量数据库是基于语义的检索。
下面给一个案例:
- 假如用户输入问题是“如何配置HTTPS?”
- 用户问题向量化Embedding,并得到问题的向量
query_vector = [0.31, 0.48, 0.73, ..., 0.15] // 768维
- 在向量数据库中搜索并匹配相似度
向量1: [0.23, 0.45, ...] → 相似度 0.45
向量2: [0.31, 0.52, ...] → 相似度 0.89
向量3: [0.12, 0.34, ...] → 相似度 0.32
......
向量8234: [0.29, 0.51, ...] → 相似度 0.91
向量8235: [0.35, 0.48, ...] → 相似度 0.87 - 返回 Top-K 最相关的,假设我们设置 K=3,返回相似度最高的3个文本块
比如说上面的向量2、8234、8235三、RAG – A(Augmented-增强)
在得到Top-K相关的数据后,会把这几条结果的原始数据和用户的问题,一起给LLM。为什么叫Augmented增强呢?
其实本质就是将提示词Prompt优化(提示词工程)。
继续上述案例,“增强”就是把Query和知识库中的相关数据,通过一些特殊的Prompt给到LLM,让LLM更好地回答问题。
四、RAG – G(Generation-生成)
最后这个Generation就和LLM没区别了,LLM会根据提示词,来回答问题并按照指定的格式来输出内容。
五、整个RAG过程
在构建好私有知识库的前提下,这个过程也说明一下吧(其实就是LLM构建知识库的过程)
- 首先就是文本的分块,也就是Token,然后有特定的Token id
- 再就是向量化Embedding
- 储存并构建向量数据库
用户开始提问,首先将用户问题 → Token → Token id → Embedding
然后开始RAG
检索Retrieval → 增强Augmented → 生成Generation
总结
这里介绍了一下RAG,还简单介绍了一下大模型的基本原理,具体的原理可以查看其他文档噢,希望这篇介绍RAG对你有帮助~