文件在操作系统看来就是一坨二进制数据,它最终是要放在磁盘上的,因为磁盘能够持久化保存数据,什么意思呢,就是说,当电脑(操作系统)关机时,文件都会被存到磁盘里头,当电脑(操作系统)开机时,操作系统会从磁盘读取文件到内存了。
文件和磁盘块(block)的关系
首先,简单介绍一下磁盘,(磁盘是物理设备,为什么可以说成分为很多块呢?这就是虚拟化)磁盘分为很多个块,每个块可以由多个扇区组成,这个块就是磁盘块(block),磁盘块是文件存储到磁盘的基本单位(不是扇区)所以,文件的实际内容就是保存到磁盘块里去了
文件存储到磁盘
我们可以把磁盘想象成一本有很多很多页的空白笔记本(每一页就是一个磁盘块 Block),我们现在的任务是把几篇不同长度的文章(文件)写进这本笔记本里。
下面介绍操作系统设计者为了解决“文件越来越大、磁盘越来越大、读写要求越来越快”这一系列矛盾的填坑史。
1. 连续分配
在连续分配中,操作系统记录文件信息的方式非常简洁。由于文件在物理上是连续的,我们只需要知道“头在哪”和“有多长”。
简单的说,就是文章有多长,我就撕下连续的几页纸给它。
- 做法:
- 文件 A 需要 3 页,我给它分配第 1、2、3 页。
- 文件 B 需要 2 页,我给它分配第 4、5 页。
- 在根目录表里只需记录:起始页号,长度。
- 如何读文件B的第二块block,但不想读出B所有文件?
- 起始页号 + 长度 – 1,将得到的磁盘号放到内存即可
- 优点:
- 支持随机访问:你想读文件的最后一部分,不需要从头读,直接算个加法就能算出物理位置,磁头直接飞过去。
- 支持顺序访问:磁头读完一块,甚至不需要移动(或者只移动极小的距离)就能读下一块。这是所有分配方式中读写速度最快的(IO吞吐量最大)。
- 遇到的问题(引入下一阶段的原因):
- 碎片问题(外碎片)
- 场景:磁盘总共空闲 1GB,但全是分散的 10MB 小坑。这时你要存一个 100MB 的视频,系统会报错“空间不足”,尽管总量是够的。
- 补救措施——紧凑 (Compaction/Defrag):
- 系统必须暂停工作,把所有文件像“俄罗斯方块”一样往一边推,把空洞挤到另一边。
- 代价:这需要移动大量数据,极度消耗时间(以前 Windows 98 时代的“磁盘碎片整理”一跑就是半天,就是这个原理)。
- 还有就是空闲磁盘记录表来补救一下磁盘空洞
- 文件扩展难
- 场景:你写了个 Word 文档,分配了块 10-15。
- 当你点击“保存”想多写一段话(需要用到块 16)时,发现块 16 已经被别人的照片占用了。
- 后果:
- 报错:无法保存。
- 搬家:系统必须在磁盘别处找一个更大的连续空间(比如块 100-110),把原来的内容全部复制过去,再追加新内容,然后删掉老地方。
- 如果你只是想给 10GB 的电影加 1KB 的字幕,却要搬运 10GB 的数据,这简直是灾难。
结论:这就逼着我们必须把文件“打散”来存。
2. 链表分配
别名:隐式链接 (Implicit Linking)
核心思想:把磁盘块看作一个链表,数据块里藏着“下一站”的地址。
1. 结构细节
- 目录项 (Directory Entry):
- 只记录:文件名、起始块号、结束块号。
- 例子:File_A -> Start: 5, End: 10。
- 物理块结构:
- 假设一个磁盘块大小是 512 字节。
- 数据区:508 字节。
- 指针区:4 字节(存放下一个块的物理地址)。
- 注意:用户虽然感觉拥有 512 字节,但实际能用的只有 508 字节。
2. 工作流程
- 读取:你想读 File_A。系统先去目录找到 Start: 5。
- 磁头读取第 5 块。
- 读完数据后,取出末尾的 4 字节指针,发现指向 23。
- 磁头移动到 23,继续读取…
- 直到读到某块的指针是 -1 (结束标记)。
3. 优缺点分析
- 优点:
- 零外部碎片:就像水一样,只要磁盘有空缝隙,就能流进去填满,不需要连续空间。
- 文件扩展容易:想把文件变大?随便找个空闲块,把当前最后一块的指针指过去就行。
- 缺点(致命伤):
- 只支持顺序访问(慢!):你想看电影的第 1 小时 30 分处的数据?对不起,不能直接跳过去。你必须从第 1 秒开始读,沿着链条一环扣一环地找。这对于数据库等随机读写的应用是灾难。
- 可靠性差:这是“串联电路”。如果链条中间的一个块坏了(扇区损坏),或者指针数据出错了,后面的所有数据瞬间丢失。
- 空间利用率别扭:因为指针占了几个字节,导致数据区的大小通常不是 2 的整数次幂(比如 512 变成了 508),这会让上层程序的缓冲区处理变得很麻烦。
为了解决链表链接随机访问速度非常慢(IO),因此就有了fat表
3. FAT表
别名:显式链接 (Explicit Linking)
核心思想:把链表分配中那个藏在磁盘块里的“指针”,全部提出来,存放到内存的一张大表里。
1. 结构细节
这是微软 DOS 和早期 Windows 的核心技术。
- 磁盘物理布局:
- FAT 区:位于磁盘开头,专门存放这张表。
- 数据区:剩下的部分存真实数据。
- FAT 表结构:它本质上是一个整数数组。
- 数组下标 (Index) = 物理块号。
- 数组内容 (Value) = 下一物理块号。
举例:假设文件 A 占用了 2、6、8 三个块。 FAT 表在内存中的样子:
| 下标 (物理块号) | 内容 (下一块在哪里) |
|---|---|
| … | … |
| 2 | 6 |
| … | … |
| 6 | 8 |
| … | … |
| 8 | -1 (EOF) |
- 目录项:只需记录 文件名 和 起始块号: 2。
2. 工作流程
- 随机访问的实现:
- 用户想找文件 A 的第 3 个块(逻辑上的第 2 块,从 0 开始算)。
- 系统不需要读磁盘,直接在内存查 FAT 表:
- 查 FAT[2] 得到 6。
- 查 FAT[6] 得到 8。
- 算出来了!目标在物理块 8。
- 磁头直接飞到第 8 块读取。
- 本质:用内存计算代替了磁盘 I/O,速度极大提升。
3. 优缺点分析
- 优点:
- 支持随机访问:虽然还是要查表,但查内存比读磁盘快百万倍。
- 数据块纯净:块里全是数据,没有指针占用空间。
- 缺点(大容量磁盘的噩梦):
- 内存占用极大:FAT 表必须常驻内存才能保证速度。
- 算一笔账:
- 假设磁盘 1TB,块大小 4KB –>总共约 2.6 亿个块。
- FAT 表就要有 2.6 亿项。每项至少要 4 字节(32位)来存编号。
- 2.6 亿 ×× 4 Bytes ≈≈ 1GB。
- 仅仅为了挂载这个硬盘,操作系统就得先吃掉你 1GB 的内存! 这在以前内存昂贵的时代是不可接受的,在现在也是巨大的浪费。
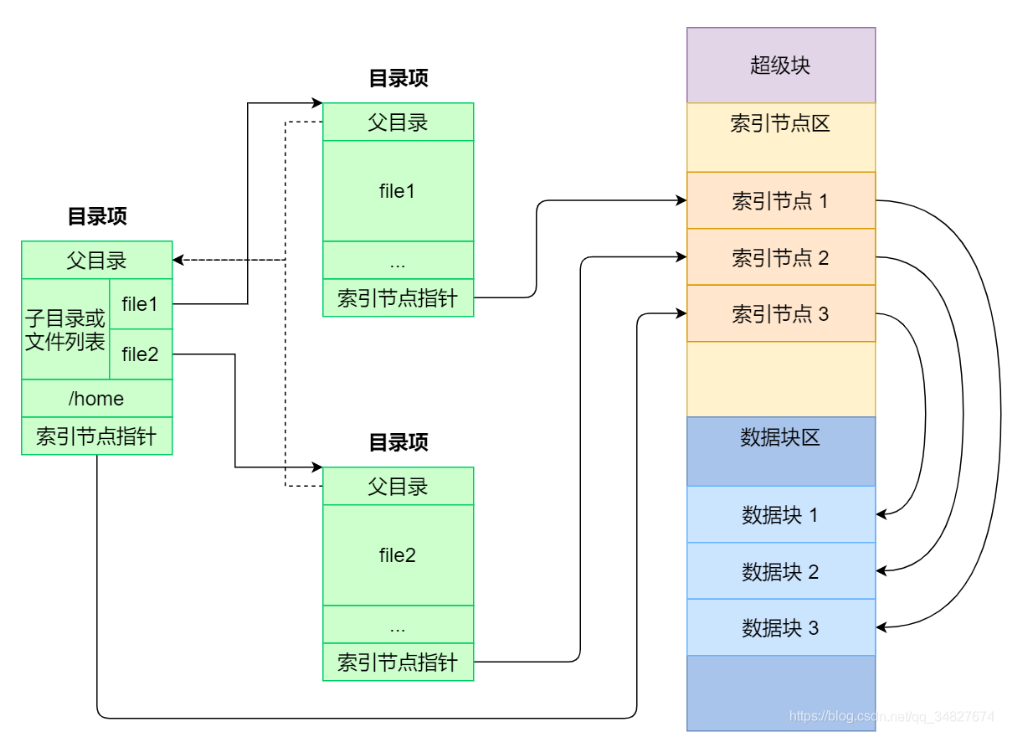
4. inode 索引节点(Indexed Allocation)
核心思想:去中心化。既然 FAT 表太大,那就把它打散。每个文件自己带一个小型的“FAT表”(即索引块),只在需要打开该文件时才把它的索引加载到内存。
1. 结构细节 (Unix/Linux 标准)
- Inode (索引节点):
- 它是一个固定大小的数据结构(比如 128 或 256 字节)。
- 包含两部分:
- 元数据:权限、所有者、大小、时间戳。
- 地址索引表 (i_addr):一个包含若干指针的数组(通常是 15 个指针)。
- 混合索引机制 (应对大小文件): 为了既能快读小文件,又能存下大文件,这 15 个指针被设计得很精妙:
- 直接指针 (Direct Pointer, 12个):直接指向存数据的物理块。
- 这能覆盖约 48KB 的小文件 (4KB * 12),访问极快,一次命中。
- 一级间接指针 (Single Indirect, 1个):指向一个“纯存放地址的块”。
- 就像目录,这个块里存了几百个物理地址。能扩展到几 MB 的文件。
- 二级间接指针 (Double Indirect, 1个):指向一个“地址块”,那个地址块里存的又是“地址块的地址”。
- 套娃两层。能支持 GB 级别的文件。
- 三级间接指针 (Triple Indirect, 1个):套娃三层。
- 支持 TB 级别的大文件。
- 直接指针 (Direct Pointer, 12个):直接指向存数据的物理块。
2. 工作流程
- 访问:
- 用户打开 File_A。系统找到其 Inode 编号,将 Inode 读入内存。
- 小文件情况:要读第 1 块?直接看 Inode.addr[0],拿到物理地址,读盘。(1次磁盘 I/O)
- 大文件情况:要读第 10000 块?
- 算出它超过了直接指针的范围,属于二级间接索引范围。
- 读 Inode 里的二级指针 →→ 读一级索引块→→ 读二级索引块→→ 拿到数据块地址。(需要额外的几次磁盘 I/O 来读索引块,但相比顺序查找依然快得多)
3. 优缺点分析
- 优点:
- 极高的内存效率:不管磁盘多大,只要我不打开文件,就不占内存。打开一个文件只加载几百字节的 Inode。
- 极佳的扩展性:小文件极其高效(直接指针),大文件也能存得下(多级索引)。
- 文件系统健壮:每个文件独立,一个 Inode 坏了通常只影响这一个文件。
- 缺点:
- 由于间接索引的存在:对于超级大文件的随机访问,可能需要多读 2-3 次磁盘(读索引块)才能读到真正的数据。
- 空间开销:如果磁盘上存了无数个 1 字节的小文件,每个文件都要配一个 Inode 和一个数据块,Inode 也是占磁盘空间的(通常占磁盘总容量的 1% 左右)。
核心对比表:四种分配方式大乱斗
| 维度 | 1. 连续分配 (Contiguous) | 2. 链表分配 (Linked) | 3. FAT 表 (Explicit Linked) | 4. Inode 索引 (Indexed) |
|---|---|---|---|---|
| 核心思想 | 数组:必须占一块连续的地盘。 | 寻宝:数据块里藏着下一块的地址。 | 地图:把所有“下一块地址”提取到内存的一张大表中。 | 目录卡:每个文件自带一张地址表(索引块)。 |
| 记录方式 | 起始块号 + 长度 | 起始块号 + 结束块号 | 内存中的 FAT 表 (数组) | 磁盘上的 Inode 结构 |
| 随机访问 | 最强 (极快) 直接算出物理地址。 | 最差 (极慢) 必须从头顺藤摸瓜。 | 较好 在内存查表,不用读盘,但仍需遍历。 | 强 (很快) 通过索引直接定位,大文件需多读级索引。 |
| 顺序访问 | 最强 磁头几乎不用动。 | 较差 磁头可能在磁盘上乱跳。 | 较好 同链表,但查表速度快。 | 较好 取决于块的物理分布。 |
| 外部碎片 | 严重 会有大量无法利用的小空洞。 | 无 见缝插针。 | 无 见缝插针。 | 无 见缝插针。 |
| 文件扩展 | 最难 后面没空位就得搬家(整体拷贝)。 | 容易 随便找个空块链上就行。 | 容易 改一下内存里的表就行。 | 容易 在索引块里加个地址就行。 |
| 内存/空间 | 极省 只需记两个数字。 | 省 指针藏在数据块里,不占额外内存。 | 极费内存 大磁盘会导致表非常大。 | 省内存 只加载打开文件的索引。 |
| 可靠性 | 高 坏一块只丢那一块。 | 低 断链 = 丢后面所有数据。 | 一般 FAT表坏了全盘完蛋(通常有双备份)。 | 高 个别索引坏了不影响其他文件。 |
| 典型应用 | 光盘(ISO9660)、磁带 | 早期系统、由于太慢现已淘汰 | DOS、Windows、U盘、SD卡 | Linux (ext4)、Unix、macOS |
总结建议
- 如果你要设计一个读取速度极快、但不许修改的文件系统 →→选 连续分配。
- 如果你要设计一个简单的、给小容量嵌入式设备用的系统 →→ 选 链表分配(或简单版 FAT)
- 如果你要兼容 Windows 和各种移动设备(U盘),且磁盘不是特别巨大 →→ 选 FAT。
- 如果你要设计一个通用的、支持海量并发、大文件、安全的现代操作系统 →→ 选 Inode。
